

Una alternativa a Stata: usando R para estimación de Modelos de Regresión
An alternative to Stata Using R for estimation of Regression Models
ACI Avances en Ciencias e Ingenierías
Universidad San Francisco de Quito, Ecuador
Recepción: 17 Agosto 2018
Aprobación: 06 Diciembre 2018
Resumen: RegUtils es un paquete implementado para el entorno y lenguaje de programación R, que contiene un conjunto de funciones destinadas a facilitar el uso de este software como una alternativa al software comercial Stata para la estimación de Modelos de Regresión. Las funciones aquí implementadas, están pensadas para facilitar la migración de modelos estimados en Stata al software R, utilizando una sintaxis en muchos sentidos equivalente a la de los comandos de Stata, pero que al mismo tiempo sea compatible con paquetes relevantes de R y los paradigmas de programación en R.
Palabras clave: Paquete RegUtils, Stata, R, migración de modelos.
Abstract: RegUtils is a package implemented for the environment and programming language R, which contains a set of functions to facilitate the use of this software as an alternative to commercial software Stata for estimating regression models. Functions within this package are designed to help with the migration of models developed in Stata to R. These are constructed keeping a syntax equivalent to Stata counterparts, while maintaining compatibility with R relevant packages and programming paradigms.
Keywords: RegUtils package, Stata, R, migration models.
INTRODUCCIÓN
El análisis estadístico en general, y en particular, la estimación de regresiones lineales y no lineales, como muchas otras áreas, se apoya en la actualidad en el uso de herramientas computacionales para este análisis. Dos de las herramientas más usadas son: R y Stata. Estas facilitan, entre otras cosas, el uso de procesos de estimación de parámetros que de otra forma serán inalcanzables, por la complejidad e intensidad del cálculo involucrado. Trabajos como [1], ilustran este punto en el contexto del manejo de grandes bases de datos multinivel longitudinales.
En muchos problemas existe una relación inherente entre dos o más vari- ables, y resulta necesario explorar la naturaleza de esta relación. El análisis de regresión es una t'ecnica estadística para el modelado y la investigación de la relación entre dos o más variables. Unas aplicaciones generales serían: líneas de tendencia en series de tiempo, relaciones causales en medicina, mod- elos econom'etricos, entre otros [2].
R es un lenguaje y entorno de programación para análisis estadístico y gráfico. Se trata de un proyecto de software libre, resultado de la implementación GNU del premiado lenguaje S. R y S-Plus -versión comercial de S- son, probablemente, los dos lenguajes más utilizados en investigación por la comunidad estadística, siendo además muy populares en el campo de la investigación biomédica, la bioinformática y las matemáticas financieras. A esto contribuye la posibilidad de cargar diferentes bibliotecas o paquetes con finalidades específicas de cálculo o procedimientos gráficos [3].
Stata es un paquete de software estadístico creado en 1985 por StataCorp. Es utilizado principalmente por instituciones académicas y empresariales dedicadas a la investigación, especialmente en economía, sociología, ciencias políticas, biomedicina y epidemiología. Stata permite, entre otras funcionalidades, la gestión de datos, el análisis estadístico, el trazado de gráficos y las simulaciones [4].
El objetivo principal de este trabajo es describir la implementación y sintaxis de un conjunto de comandos paralelos a la oferta de Stata, a fin de facilitar el uso de R para quienes están familiarizados o vienen de un entorno en el que se usaba principalmente Stata. Estos comandos se escogieron luego de analizar la oferta de modelos de regresión tanto en Stata como en R. La sección 2 de este trabajo ilustra el modelo teórico de cada procedimiento contenido en RegUtils. Luego, en la sección 3 se describe brevemente los pasos para la instalación y uso de RegUtils. La sección 4 presenta los resultados de la implementación de RegUtils donde se evidencia la equivalencia entre R y Stata. Finalmente, el trabajo concluye presentando las conclusiones y posibles desarrollos posteriores.
MARCO TEÓRICO
Se han revisado 35 comandos Stata (ver anexo 1), 5 de ellos (14%) no tu- vieron una equivalencia directa en R. Estos son: areg, comando que aborda los modelos de regresiones lineales de grandes conjuntos en variables binarias. boxcox, es un comando que maneja modelos de regresión con sus transformaciones. eivreg se utiliza para modelos de regresión de errores en las variables. etregress, maneja modelos de regresión lineal con efectos de tratamiento endógeno. ivtobit se usa para la estimación de modelos de regresión tobit con variables endógenas.
Las siguientes subsecciones están organizadas de tal manera que el lector pueda familiarizarse con la descripción y el modelo asociado a cada comando implementado
Regresión Lineal con conjuntos grandes de variables binarias (areg)
Descripción
Este modelo se utiliza cuando se desea ajustar un modelo de regresión lineal que tenga factores dentro del conjunto de variables explicativas de modo que el ajuste implique el uso de un gran número de variables binarias al momento de generar la matriz de diseño.
Modelo
Suponga que desea estimar una regresión con un gran número de variables binarias a partir de n individuos:
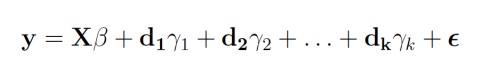 (1)
(1)donde y es de dimensión n x 1, X (de dimensión n x p donde p es el número de columnas de la matriz de diseño) es la matriz de variables explicativas (sin incluir las variables binarias), di son las variables binarias, son los coeficientes de las variables binarias y ∈ es el error [5].
Modelos de Regresión con transformaciones de Box Cox (boxcox)
Descripción
Este modelo se utiliza para estimar -usando el método de máxima verosimilitud- los parámetros de regresión de variables a las cuales se les ha aplicado la transformación de Box-Cox.
Modelo
En su trabajo seminal, [6] proponen una transformación de los datos que es útil para reducir el sesgo, estabilizar la varianza y concebir que los datos tengan una distribución más parecida a una normal, entre otras [7]. De entre los modelos lhsonly, rhsonly, lambda y theta que ofrece Box-Cox, para el ejemplo se utilizó el modelo theta:
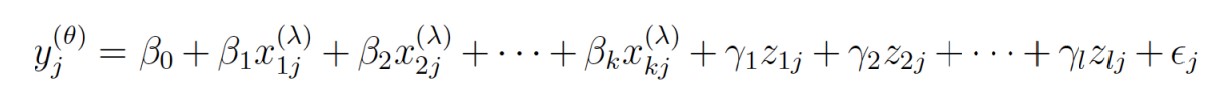 (2)
(2)donde ∈~N(0,σ2), y está sujeta a una transformación Box-Cox con parámetro λ y cada x1, x2, . . . , xk son transformadas por Box-Cox con parámetro 2. Las variables z1, z2, . . . zl son covariables no transformadas [4].
Modelos de regresión con errores en las variables (eivreg)
Descripción
Este modelo implica el ajuste de regresiones en las cuales una o más variables independientes son medidas con ruido aditivo. El sesgo introducido por este ruido trata de ser compensando mediante el uso de un coeficiente de confiabilidad.
Modelo
Si una covariable del modelo tiene un error de medición, una regresión tradicional no estimaría adecuadamente su efecto. Además, los coeficientes de las demás covariables del modelo podrían estar sesgados debido a la presencia en el modelo de esa variable. Se puede ajustar el sesgo si se conoce la confiabilidad (reliability):
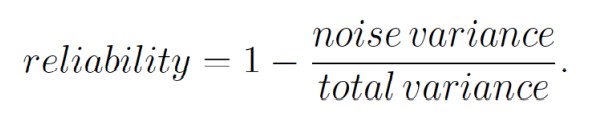 (3)
(3)Esto es, dado el modelo
para alguna variable xi en X , xi es observada con error, xi = + e y la varianza de ruido es la varianza de e. La varianza total es la varianza de xi [4]
Modelos de regresión lineal con efectos de tratamiento endógeno (etregress)
Descripción
Este modelo estima los parámetros de una regresión aumentada con una variable binaria endógena, donde el principal objetivo generalmente es parámetro que captura el efecto promedio en el tratamiento (average treatment effect - ATE). Esta variable endógena debe estar correlacionada con el tratamiento pero no con el error ni las variables explicativas del modelo principal.
Modelo
El modelo de regresión de efectos de tratamiento endógeno está compuesto de una ecuación para el resultado yj y una ecuación para el tratamiento endógeno tj,
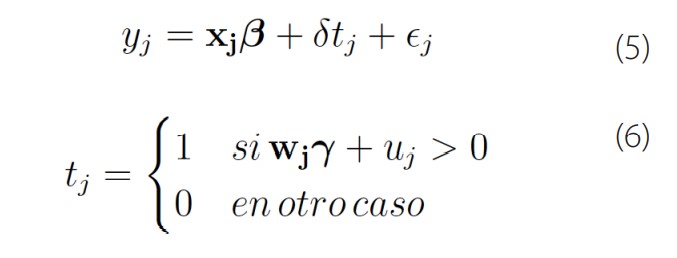
Donde xj son las covariables del modelo principal, wj son covariables usadas para modelar el tratamiento, y los términos de error ∈j y ujtienen una distribución normal bivariada con media cero y matriz de covarianza:
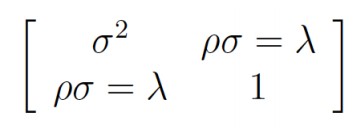 (7)
(7)Las covariables xj y wj son exógenas, esto es, no están correlacionadas con el término de error [4].
Modelo de regresión tobit con variables endógenas (ivtobit)
Descripción
Corresponde a modelos tobit donde una o más de las variables regresoras son determinadas endógenamente.
Modelo
El modelo es:
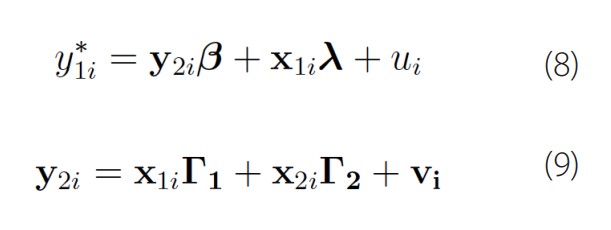
donde i = 1 N ; y2i es un vector 1 x p de variables endógenas; x1i es un vector 1 x k 1 de variables exógenas; x2i es un vector 1 x k2 de instrumentos adicionales; y la ecuación y2i está escrita en forma reducida. El modelo supone que (ui,vi)~N(0). β y λ son vectores de parámetros instrumentales, Γ1 y Γ2 son matrices de parámetros de forma reducida. y es observada en forma censurada [7].
INSTALACIÓN
Como se ha mencionado, el anexo 1 contiene la información de todos los comandos investigados y sus paralelos entre Stata y R. La tabla 7 muestra los comados que han sido desarrollados exclusivamente en RegUtils.
| Comando en Stata | Comando en R | Descripción |
| areg | alm | Ajusta regresiones con variables dummy |
| boxcox | boxcox.r | Modelos de regresión Box-Cox |
| eivreg | eivlm | Regresión con errores en las variables |
| etregress | etreg | Regresión lineal con efectos endógenos |
| ivtobit | ivtobit | Regresión tobit con variables endógenas |
Comandos implementados en RegUtils. Fuente: [3] y [4]. Elaboración propia
Actualmente el paquete se encuentra en el repositorio Github: https://github.com/bolimorales/RegUtils. Para utilizarlo se deben realizar los siguientes pasos:
library(devtools)
install github(“bolimorales/RegUtils”)
Como es usual en los paquetes de R, se puede acceder a la ayuda de cada una de las funciones de la tabla 7. Por ejemplo, para acceder a la ayuda de etreg se ejecuta: help(etreg).
ESTIMACIÓN DE MODELOS
A continuación se presentan los resultados obtenidos de cada una de las funciones del paquete RegUtils. Note que se mantiene consistencia con el marco teórico. Es decir, cada uno de los modelos presentados en la sección 2 es ilustrado mediante ejemplos y su respectivo contraste entre R y Stata.
Regresión Lineal con conjuntos grandes de variables binarias (areg)
Ejemplo
Se dispone de un conjunto de datos que describen las características de 74 autos. Las variables de interés se muestran en la tabla 2:

Datos para la regresión con variables binarias. Fuente: [4]. Elaboración propia.
Se desea explicar las millas por galón en función de las demás variables presentadas en la tabla anterior. Una forma de resolver el problema es ajustar un modelo de regresión tradicional, lo cual precisaría de 4 niveles para el factor rep78. Sin embargo, areg permite, en lugar de realizar una prueba t para cada coeficiente, hacer una prueba F conjunta para todos los niveles de un determinado factor. Este proceso permite trabajar de forma eficiente sobre conjuntos de datos donde la cantidad de variables binarias generadas es muy grande, pero tambi'en nos permite centrar el análisis en un conjunto de variables independientes al margen de los grupos creados por las variables binarias [5].
Aplicación
Aquí se ajusta el modelo descrito en la parte anterior tanto en Stata (figura 1a) como en R (figura 1b).

Resultados de la regresión con variables binarias en Stata y R. Fuente y elaboración: autores
Note que el comando especifica absorb(rep78), esto indica que se aplica una prueba F sobre el conjunto de los niveles de la variable rep78. Su valor p indica que, en conjunto, los niveles de rep78 no son significativos a un α = 0.05. Es decir que los niveles de rep78 no influyen en las millas por galón. Además, los coeficientes de las demás variables se ajustan en forma estándar.
El resultado puede escribirse de la siguiente manera:
 (10)
(10)Se aprecia que los niveles de la variable rep78 no se imprimen debido al método utilizado para obtener más eficiencia, es decir, la prueba F . Note que los coeficientes para weight, gear ratio y la constante son exactamente los mismos al igual que el error estándar, valores t y, consecuentemente, el valor p (ver tablas de coeficientes). En la salida estándar de R no se reportan los intervalos de confianza para los coeficientes pero estos se pueden obtener a través del comando confint (usando el modelo guardado en fit1) con el que se obtiene los mismos valores (con una pequeña diferencia en el intercepto).
El primer estadístico F (igual a 41.64) mostrado en la salida de Stata corresponde al Chi-cuadrado del test de Wald (83.28) (ubicado al final de la salida de R en la figura 1b), dividido para los grados de libertad, es decir 41.64 = 83.28/2. En ambos casos el Chi-cuadrado por lo que la conclusión de la prueba es la misma.
También se observa que coinciden el R2, el R2 ajustado y los errores estándar residuales (MSE) = 3.511, los cuales suelen utilizarse para evaluar la bondad de ajuste de la regresión. La prueba F para rep78, no se presenta de forma estándar en R, pero se puede calcular mediante el comando anova con el que se obtiene el mismo valor, esto es, 1.117.
Regresión con transformaciones de Box Cox (box- cox)
Ejemplo
A continuación se utiliza un subconjunto de datos de la Segunda Encuesta Nacional de Salud y Nutrición (NHANES II), para crear un modelo de estimación del nivel individual de presión arterial. Las variables a utilizar en el modelo se muestran en la tabla 3.
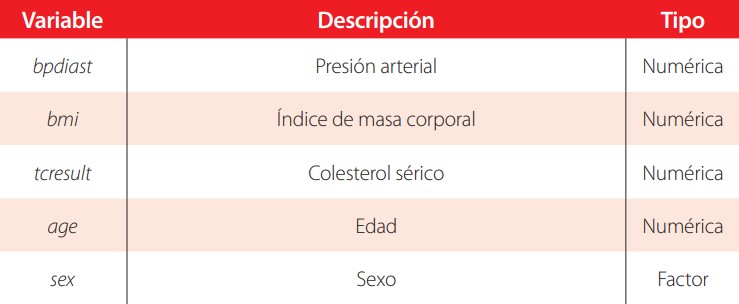
Datos para la regresión con transformaciones de BoxCox. Fuente: [4]. Elaboración propia
Con el objeto de corregir la no linealidad en la relación con las variables se calcula la transformación de Box-Cox para las variables bmi, y tcresult, así como la transformación de la variable dependiente dentro del modelo de regresión.
Aplicación
Para estimar este modelo se utiliza en R el comando boxcox, parte del paquete RegUtils; en Stata se utiliza el comando boxcox. Estos comandos permiten estimar varios tipos de modelos que incluyen el modelo lambda, donde se usa el mismo parámetro de transformación sobre todas las variables, modelos theta, que utilizan un parámetro diferente para la variable independiente, y modelos que mezclan variables transformadas y no transformadas. Los dos comandos permiten especificar un subconjunto de variables independientes a las cuales no se aplicará la transformación. En la figura 2b se muestran los resultados del ejemplo.
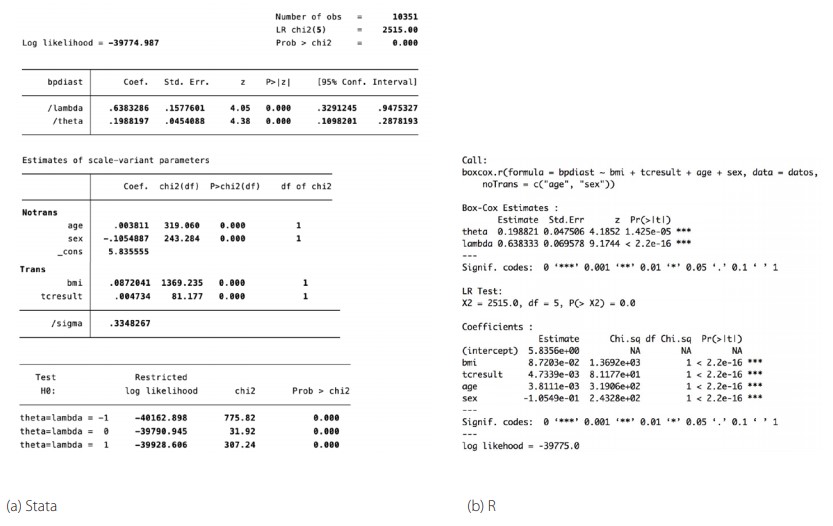
Resultados de la regresión con transformaciones de BoxCox en Stata y R. Fuente y elaboración: autores
Se escribe los resultados de la siguiente manera:
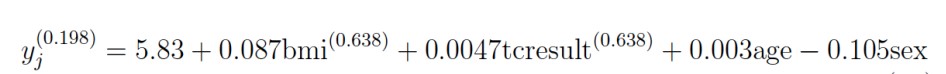 (11)
(11)Se aprecia que todos los coeficientes son significativos a un α = 0.05 como se verifica en la figura 2b. Los coeficientes para lambda y theta coinciden, así como sus pruebas de hipótesis. Se presenta además el mismo número de observaciones, la misma estimación para sigma y de la verosimilitud, -39775. Para realizar la prueba del ratio de verosimilitudes en R se puede usar el comando logLik.ratio.test del paquete RegUtils.
Regresión con errores en las variables (eivreg)
Ejemplo
Se utiliza datos de una industria automotriz. Se asume que el peso de los autos es medido con ruido aditivo que puede ser aproximado por una confiabilidad de 0.85. Bajo este supuesto se realiza un modelo de regresión lineal simple para el precio utilizando las variables que se detallan en la tabla 4:
| Variable | Descripción | Tipo |
| price | Precio | Numérica |
| weight | peso en libras | Numérica |
| foreign | Extranjero | Binaria |
Datos para la regresión con errores en las variables. Fuente: [4].Elaboración propia.
Aplicación
En Stata el comando eivreg ajusta modelos de regresión con errores en las variables. En R se implementó el comando eivlm como parte del paquete RegUtils. En la figura 3 se muestran los resultados en Stata y R.
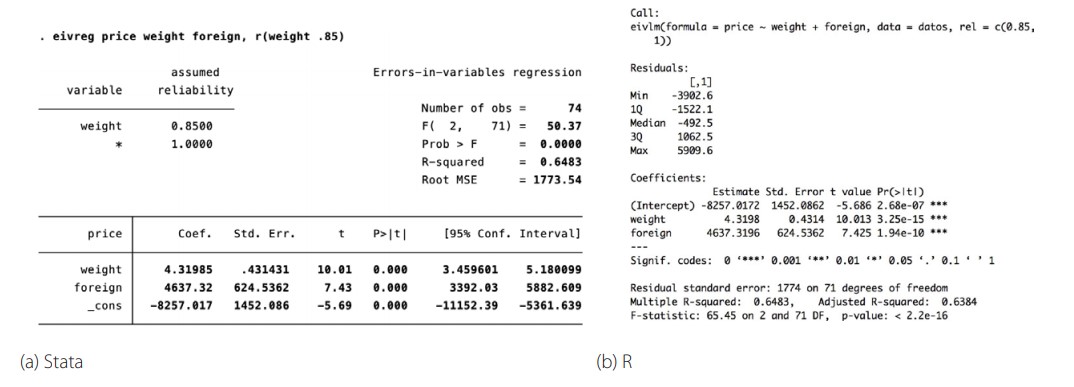
Resultados de la regresión con errores en las variables en Stata y R. Fuente y elaboración: autores
Se puede escribir los resultados de la siguiente manera:
 (12)
(12)Los coeficientes habrían sido menores de no haber tomado en cuenta la medición con error de la variable weight (Ver [14] para más detalles de este tipo de modelos). El coeficiente de confiabilidad afecta el coeficiente y el error estándar obtenidos para la variable peso. Además se observa que los coeficientes de los parámetros y las pruebas de hipótesis coinciden.
Modelos de regresión lineal con efectos de tratamiento endógeno (etregress)
Ejemplo
Se utiliza un subconjunto de la base de datos sobre ingresos de mujeres de Estados Unidos en 1972 con edades entre 18 y 30 años, para modelar los efectos promedios en el tratamiento para la variable union (pertenece o no a un sindicato) sobre el ingreso. Las variables a ser incluidas en el modelo se detallan en la tabla 5.
| Variable | Descripción | Tipo |
| wage | Ingreso | Numérica |
| grade | Años de instrucción | Numérica |
| smsa | Variable indicativa de pertenencia a un distrito estadístico | Binaria |
| black | Variable indicativa para Afro-Americanos | Binaria |
| tenure | Permanencia en el trabajo actual | Numérica |
| south | Variable indicativa para residencia en el sur | Binaria |
Datos para la regresión lineal con efectos de tratamiento endógenos. Fuente: [4].
De estas variables se utiliza south, black y tenure para modelar la variable endógena unión.
Aplicación
Para estimar el modelo se emplea el comando etregress en Stata y el comando etreg del paquete RegUtils en R. En la figura 5 se muestran los resultados obtenidos.
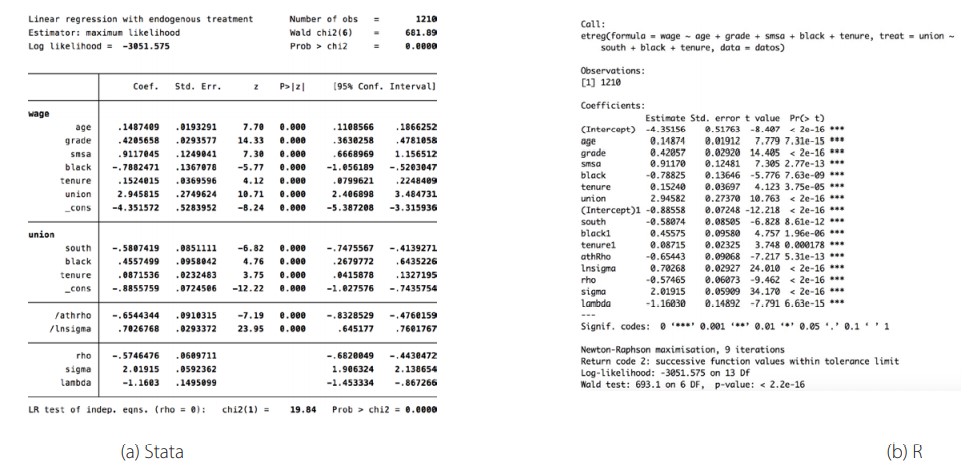
Resultados de la regresión lineal con efectos de tratamiento endógenos en Stata y R.
El modelo ajustado del ejemplo sería:

Se observa en la figura 8 que los coeficientes son significativos y que el efecto. de tratamiento endógeno (coeficiente de union) es 2.94
Modelo de regresión tobit con variables endógenas (ivtobit)
Ejemplo
Se utiliza a continuación datos de ingresos de un grupo de mujeres asumiendo que todas las mujeres que deciden no trabajar reciben $ 10,000 en pagos de asistencia social y la manutención de los hijos. En el modelo se incluirán las variables que se muestran en la tabla 6:
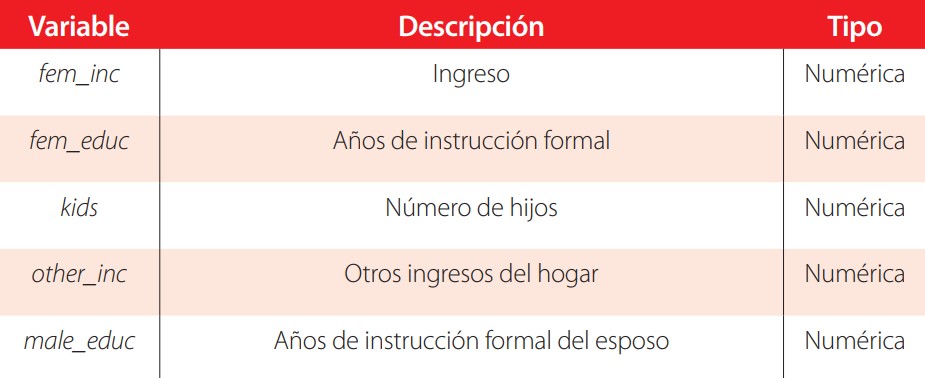
Datos para la regresión tobit con variables endógenas. Fuente: [4]. Elaboración propia.
En el modelo se considera la varibale other_inc como endógena, motivo por la cual se utiliza la variable male_educ como variable instrumental.
Aplicación
Para estimar el modelo se utiliza el comando ivtobit de Stata. En R se usa el comando del mismo nombre implementado como parte del paquete RegUtils. La figura 5 muestra los resultados obtenidos.
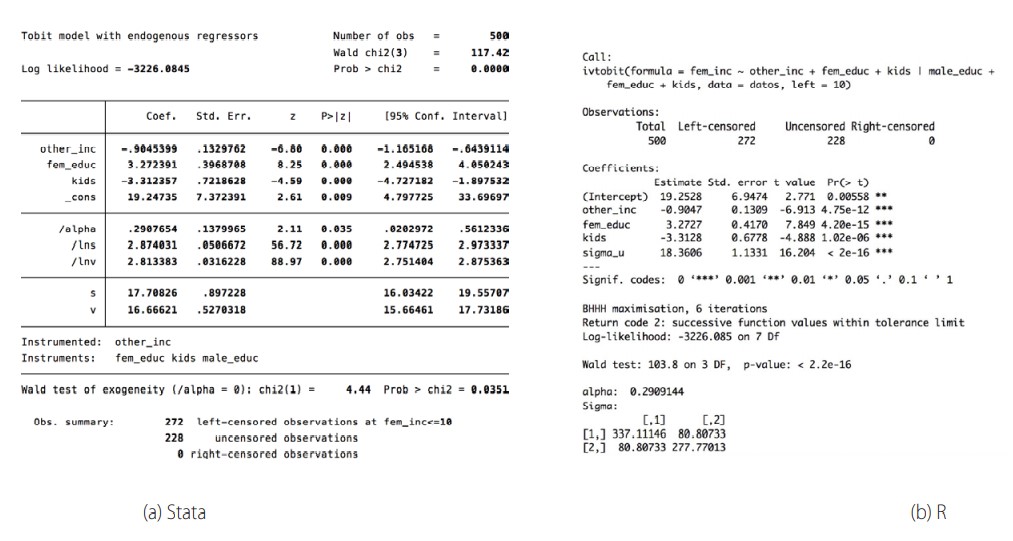
Resultados de la regresión tobit con variables endógenas en Stata y R. Fuente y elaboración: autores
El modelo estimado es:
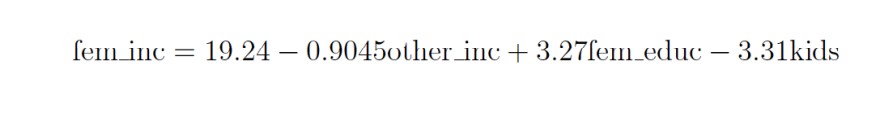 (16)
(16)En ambos comandos el estimador se calcula utilizando el método de máxima verosimilitud. Todas las variables del modelo son estadísticamente significativas a un a = 0.05 y se aprecia que son los mismos valores.
CONCLUSIONES
El uso del paquete RegUtils, sin duda es una herramienta muy útil para usuarios que desean migrar o usar simultáneamente R y Stata dado que permite obtener modelos similares a aquellos ajustados con los comandos de Stata, con una sintaxis que resulta muy fácil de equiparar con la de Stata.
El paquete facilita que estos modelos se integren con otras funcionalidades y comandos de R. Sin embargo, se recomienda que una vez que se alcance el nivel adecuado de familiaridad con R, se explore otros paquetes y rutinas propias del lenguaje que, sin tener las mismas salidas de Stata pueden conducirnos al ajuste de modelos de utilidad.
Utilizar los comandos implementados en R para el manejo de estos modelos conlleva algunas ventajas sobre el software propietario, se podría mencionar entre estas el hecho de que no tendría costo para el usuario. Además, R es versátil para el desarrollo de rutinas, acceso al código para aprender de él y modificarlo en función de las necesidades del investigador y facilidades para el trabajo colaborativo al poder compartir análisis sin preocupación de que el receptor disponga de las licencias.
Como todos los proyectos realizados en R, se recomienda que todo usuario interesado se motive en generar retroalimentación para su perfeccionamiento. Por ejemplo podría colaborar con paquetes o correcciones de paquetes existentes en el Comprehensive R Archive Network - CRAN. También se puede contribuir a mejorar las rutinas del paquete RegUtils, ya que el código se encuentra disponible en el sitio github.
Referencias
D. F. McCaffrey, J. R. Lockwood, K. Mihaly, T. R. Sass, et al., A review of stata commands for fixed-effects estimation in nor- mal linear models, Stata Journal, 12 (2012), p.406.
R Core Team, R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria, 2017.
StataCorp, Stata 15 Base Reference Manual, Stata Press, College Station, TX, 2017.
M. C. Lovell, A simple proof of the fwl (frisch-waugh-lovell) theorem. 2006.
G. E. Box and D. R. Cox, An analysis of transformations, Journal of the Royal Statistical Society. Series B (Methodological), (1964), pp. 211- 252.
J. M. Wooldridge, Introducción a la eammetr'ia: un enfoque moderno, Editorial Paraninfo, 2006.
A. Henningsen and O. Toomet, maxlik: A package for maximum likelihood estimation in R, Computational Statistics, 26 (2011),pp.443-458.
A. Zeileis and Y. Croissant, Extended model formulas in R: Mul- tiple parts and multiple responses, Journal of Statistical Software, 34 (2010), pp. 1-13.
J. Fox and S. Weisberg, An R Companion to Applied Regression, Sage, Thousand Oaks CA, second ed., 2011.
A. Zeileis, Econometric computing with hc and hac covariance matrix estimators, Journal of Statistical Software, 11 (2004).
A. Henningsen, censReg: Censored Regression (Tobit) Models, 2017. R package version 0.5-26.
H. Wickham and W. Chang, devtools: Tools to Make Developing R Packages Easier, 2017. R package version 1.13.4.
N. R. Draper and H. Smith, Applied regression analysis, vol. 326, John Wiley & Sons, 2014.
B. Morales-Oñate, C. Jiménez-Mosquera, P. Mendez, and V. Morales-Oñate, RegUtils: Tools for STATA users in Regression Models Estimation, 2015. R package version 0.1.
A. Ghalanos, rugarch: Univariate GARCH models., 2018. R package version 1.4-0.
D. Wuertz, T. Setz, and Y. Chalabi, fArma: Rmetrics - Modelling ARMA Time Series Processes, 2017. R package version 3042.81.
T. Coelli and A. Henningsen, frontier: Stochastic Frontier Analysis, 2017. R package version1.1-2.
P. Chaussé, Computing generalized method ofmoments and generalized empirical likelihood with R, Journal of Statistical Software, 34 (2010), pp. 1-35.
O. Toomet and A. Henningsen, Sample selection models in R: Package sample Selection, Journal of Statistical Software, 27 (2008).
O. Toomet, intReg: Interval Regression, 2015. R package version 0.2-8.
C. Kleiber and A. Zeileis, Applied Econometrics with R, Springer- Verlag, New York, 2008. ISBN 978-0-387-77316-2.
A. Henningsen and J. D. Hamann, systemfit: A package for estimating systems ofsimultaneous equations in r, Journal of Statistical Software, 23 (2007), pp. 1-40.
R. Koenker, quantreg: Quantile Regression, 2017. R package version 5.34.
W. N. Venables and B. D. Ripley, Modern Applied Statistics with S, Springer, New York, fourth ed., 2002. ISBN 0-38795457-0.
Y. Rosseel, lavaan: An R package forstructural equation modeling, Journal ofStatistical Software, 48 (2012), pp. 1-36.
Y. Croissant and A. Zeileis, truncreg: Truncated Gaussian Regres- sion Models, 2016. R package version 0.2-4.
G. Millo, Robust standard error estimators for panel models: A unifying approach, Journal of Statistical Software, 82 (2017), pp.1-27.
K. Kashin, panelAR: Estimation of Linear AR(1) Panel Data Models with Cross-Sectional Heteroskedasticity and/or Correlation, 2014. R package version 0.1.
J. Pinheiro, D. Bates, S. DebRoy, D. Sarkar, and R Core Team, nlme: Linear and Nonlinear Mixed Effects Models, 2017. R package version 3.1-131.