

Artículos
Un algoritmo simple y eficiente para la clasificación automática de páginas web
ACI Avances en Ciencias e Ingenierías
Universidad San Francisco de Quito, Ecuador
ISSN: 1390-5384
ISSN-e: 2528-7788
Periodicidad: Bianual
vol. 1, núm. 1, 2008
Publicación: 01 Abril 2009

Resumen: Este art´ıculo propone un simple pero eficiente clasificador de pa´ginas Web basado en la frecuencia de te´rmi- nos. La simplicidad esta´ dada por el uso de un conjunto pequen˜o de te´rminos para describir cada clase, mientras que la eficiencia es alcanzada mediante embolsamiento. El uso de atributos simples como la fre- cuencia de te´rminos tambie´n reduce la complejidad de los algoritmos de preprocesamiento y extraccio´n de caracter´ısticas. Sin embargo, un problema de usar propiedades dependientes de los te´rminos incluidos en cada pa´gina es la seleccio´n de la descripcio´n de te´rminos correspondiente para cada una de las clases. En este trabajo, la seleccio´n de te´rminos para cada clase se basa en el coeficiente TFIDF, mientras que el enbol- samiento utiliza clasificadores probados como redes neuronales y algoritmos bayesianos. Los resultados de nuestra evaluacio´n muestran un clasificador sumamente ra´pido con una exactitud superior al 83 %.
Palabras clave: Miner´ıa de datos, clasificacio´n, frecuencia de te´rminos, embolsamiento, World Wide Web.
Introduccio´n
La clasificacio´n o caracterizacio´n de pa´ginas Web es el proceso mediante el cual se asigna una o ma´s etiquetas predefinidas a cada documento expuesto en la Web. La tarea de clasificacio´n es a menudo vista como un proble- ma de aprendizaje supervisado en el cual un conjunto de datos previamente etiquetados es usado para entrenar un clasificador que puede posteriormente ser aplicado para etiquetar ejemplos futuros [1].
La clasificacio´n de pa´ginas Web es esencial para mu- chos procesos de administracio´n y recuperacio´n de in- formacio´n como el rastreo focalizado de pa´ginas Web
[2] y el desarrollo asistido de directorios [3]. La clasifi- cacio´n de pa´ginas Web puede tambie´n mejorar la cali- dad de las bu´squedas mediante el filtrado de contenido [4, 5] y la navegacio´n asistida [6]. Basados en la impor- tancia de estas aplicaciones y en el ra´pido crecimiento de la Web, consideramos que la clasificacio´n automa´tica de pa´ginas asumira´ un rol preponderante en los futuros servicios de bu´squeda.
Sin embargo, la naturaleza incontrolable de los conte- nidos Web genera desaf´ıos adicionales para la imple- mentacio´n de una clasificacio´n correcta y eficiente [7]. Las pa´ginas Web normalmente contienen ruido, como anuncios y barras de navegacio´n, que impide la aplica- cio´n directa de la mayor´ıa de me´todos convencionales de clasificacio´n. El ruido intr´ınseco de las pa´ginas Web produce desviaciones significativas dentro de cualquier algoritmo de clasificacio´n, haciendo que se pierda fa´cil- mente la orientacio´n sobre el to´pico principal de su con- tenido.
Adicionalmente, el disen˜o de un clasificador requiere balancear el compromiso existente entre exactitud y eficiencia. Clasificadores sumamente exactos requieren al- goritmos complejos y costosos, reduciendo su eficiencia desde el punto de vista de desempen˜o. Clasificadores ra´pidos, por otro lado, no son del todo exactos. De lo expuesto hasta el momento, adema´s de perseguir exac- titud en la clasificacio´n, los clasificadores de pa´ginas Web requieren considerar la complejidad de los algorit- mos a implementar de manera que puedan mantener sus requisitos computacionales en niveles razonables. Esta condicio´n es ma´s cr´ıtica todav´ıa si consideramos que la mayor´ıa de aplicaciones mencionadas anteriormente re- quieren clasificar cientos o inclusive miles de pa´ginas por segundo.
Fundamentados en esto, nosotros proponemos un clasi- ficador de pa´ginas Web que se basa en la frecuencia de te´rminos, principalmente. El uso de un atributo tan sim- ple como la frecuencia de te´rminos permite reducir la complejidad del clasificador y alcanzar un buen desem- pen˜o. Adema´s de alto desempen˜o, nuestro clasificador tambie´n busca exactitud y por ello emplea varios algo- ritmos ya probados como redes neuronales [8] y clasifi- cadores bayesianos [9] combinados mediante la te´cnica denominada embolsamiento [10].
Con la finalidad de lograr los objetivos propuestos, tener una implementacio´n modular y permitir una eva- luacio´n pormenorizada, nuestro clasificador de pa´ginas Web consta de tres etapas claramente definidas: el pre- procesamiento de las pa´ginas, su clasificacio´n misma y la etapa de entrenamiento de los clasificadores. La etapa de preprocesamiento consiste en una serie de filtros que extraen la mayor´ıa de te´rminos requeridos para discri- minar las diferentes pa´ginas, reduciendo la dimensiona- lidad de la informacio´n a tratar. Los algoritmos de pre- procesamiento presentan una complejidad lineal con el taman˜o del documento. Por su parte, la tarea de clasificacio´n aplica el conjunto de caracter´ısticas sintetizadas en la fase de preprocesamiento a un conjunto de clasifi- cadores previamente entrenados. Varios algoritmos de clasificacio´n simples son agrupados mediante embol- samiento con la finalidad de aumentar la exactitud de la clasificacio´n. Finalmente, la etapa de entrenamiento tiene por objetivo construir el modelo de clasificacio´n usando ejemplos de pa´ginas Web previamente catego- rizadas. Esta etapa es realizada una sola vez fuera de línea.
Antes de describir con mayores detalles la estructura propuesta para nuestro clasificador, revisemos algunos fundamentos teo´ricos usados en nuestro trabajo.
Fundamentos Teo´ricos
En esta seccio´n se introducen los diferentes tipos de clasificacio´n existentes en el contexto de las pa´ginas Web, la forma de calcular el coeficiente TFIDF y la teor´ıa detra´s de la te´cnica de embolsamiento.
Clasificacio´n de Pa´ginas Web. El problema general de clasificar pa´ginas Web puede ser dividido en mu´ltiples subproblemas: clasificacio´n tema´tica, clasificacio´n fun- cional, clasificacio´n sentimental, entre otras [7]. Nues- tro trabajo se centra en la clasificacio´n tema´tica, la mis- ma que esta´ orientada a distinguir el to´pico principal de cada pa´gina Web.
Desde el punto de vista de la clasificacio´n misma, es- ta tarea puede depender del nu´mero de clases existentes (clasificacio´n binaria o de mu´ltiples clases), del nu´me- ro de clases que pueden ser asignadas (clasificacio´n con etiqueta u´nica o de mu´ltiples etiquetas), del tipo de asig- nacio´n permitida (clasificacio´n r´ıgida o variable) y de la organizacio´n de las categor´ıas (clasificacio´n plana o jera´rquica). El presente estudio se enfoca en la clasifica- cio´n de mu´ltiples clases usando una sola etiqueta cuya asignacio´n es r´ıgida (i.e., no se permite estados interme- diarios) y las clases presentan una estructura plana.
El Coeficiente TFIDF. El coeficiente TFIDF (Term Fre- quency–Inverse Document Frequency) [11] es una pon- deracio´n usada a menudo en tareas de recuperacio´n de informacio´n y miner´ıa de texto. El coeficiente es una medida estad´ıstica usada para evaluar cuan importante es una palabra respecto a un documento perteneciente a una coleccio´n o cuerpo de documentos. La importancia de cada palabra incrementa proporcionalmente con el nu´mero de veces que ella aparece en el documento pe- ro se ve influenciada por la frecuencia de la palabra en el cuerpo de documentos. Variaciones del esquema de ponderacio´n TFIDF son usados a menudo por los moto- res de bu´squeda como una herramienta para la puntua- cio´n y ranqueo de la relevancia de un documento ante una consulta de usuario determinada.
La frecuencia de un te´rmino (TF) en un documento dado es simplemente el nu´mero de veces que el te´rmino apa- rece en ese documento. Este valor es usualmente norma- lizado para prevenir que documentos extensos adquie- ran una inusual ventaja. De esta forma, la importancia del término ti en el documento dj está dada por:
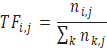 [1]
[1]Donde
es el número de ocurrencias de término considerado en el documento dj, y el denominador es el número de ocurrencias de todos los términos en el documento dj.
La frecuencia inversa de los documentos (IDF) es una medida de la importancia general del término y se calcula mediante:
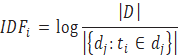 [2]
[2]donde el numerador es el nu´mero total de documentos en el cuerpo y el denominador es el nu´mero de documentos donde el te´rmino .. aparece (i.e., ni,j = 0).
Ası, el coeficiente TFIDF para el termino .. en el documento .. es:
TFIDFi,j = TFi,j x IDF.
Un valor TFIDF alto es alcanzado por un te´rmino con alta frecuencia en el documento considerado, pero baja frecuencia en la coleccio´n total de documentos. De esta manera, el coeficiente tiende a filtrar te´rminos comunes.
Embolsamiento
Embolsamiento. Este es un concepto asociado al a´rea de miner´ıa de datos y se aplica principalmente a la ta- rea de clasificacio´n. La idea central del embolsamiento es combinar la salida de varios clasificadores o predicto- res individuales implementados muchas veces por te´cni- cas de modelamiento distintas, pero entrenados bajo un mismo conjunto de datos. La combinacio´n de la salida de los varios clasificadores se lleva a cabo mediante un simple mecanismo de votacio´n.
Esta te´cnica se usa para contrarrestar las deficiencias de cada uno de los clasificadores individuales, adema´s de reducir la inestabilidad inherente de los resultados cuan- do se tienen modelos complejos aplicados a conjuntos de datos pequen˜os. De esta forma, un clasificador ba- sado en embolsamiento tiene normalmente una mayor exactitud que cualquier te´cnica de clasificacio´n indivi- dual entrenada con el mismo conjunto de datos. Adi- cionalmente, el embolsamiento ayuda a incrementar la robustez del clasificador ante el ingreso de datos ruido- sos, ya que el modelo compuesto reduce la varianza de los clasificadores individuales.
Breiman [10] inclusive mostro´ que el embolsamiento es principalmente efectivo en algoritmos de aprendiza- je “inestables” como redes neuronales y a´rboles de de- cisio´n, donde pequen˜os cambios en el conjunto de en- trenamiento producen grandes variaciones en su prediccio´n.
Clasificador Basado en la Frecuencia de Te´rminos
Nuestro clasificador incluye dos tareas fundamentales y completamente aisladas: el preprocesamiento de la pa´gi- na Web y su correspondiente clasificacio´n. Sin embargo, una tercera tarea llevada a cabo una sola vez es tambie´n incluida: el entrenamiento de los clasificadores. Estas tres tareas son descritas a continuacio´n
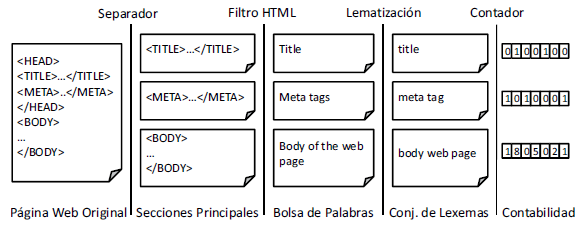
Preprocesamiento.
Preprocesamiento. La tarea de preprocesamiento pue- de ser descrita de una manera gra´fica mediante el dia- grama de la figura 1. Podemos ver que cada pa´gina Web es descargada y separada en tres secciones: (i) el t´ıtulo de la pa´gina, (ii) sus meta datos, y (iii) el cuerpo mismo del documento. Esta´ divisio´n esta´ justificada por la alta relevancia que tienen elementos como el t´ıtulo y los me- ta datos en la deficio´n del to´pico principal de una pa´gina Web [12]. Mediante esta divisio´n se permite ponderar dina´micamente la importancia relativa de cada seccio´n.
Las tres secciones son entonces filtradas de manera in- dependiente para eliminar todas sus etiquetas HTML. De esta forma, cada seccio´n se convierte en una bolsa de palabras sin ningu´n tipo de formatacio´n. Posterio- mente, cada bolsa de palabras es procesada mediante el algorimo de Paice/Husk para encontrar los lexemas o ra´ıces comunes de cada palabra. El uso de lexemas en lugar de sus variantes morfolo´gicas tiene la ventaja de incrementar la tasa de asociacio´n al agrupar te´rminos con igual ra´ız a pesar de sus terminaciones diferentes.
Finalmente, los lexemas resultantes son filtrados confor- me el conjunto de te´rminos relevantes para la mayor´ıa de categor´ıas. El conjunto de te´rminos relevantes para cada categor´ıa es obtenido mediante la seleccio´n de los lexemas con mayor valor TFIDF dentro de su respec- tivo conjunto de pa´ginas Web de entrenamiento. Cada categor´ıa aporta con un nu´mero pequen˜o de te´rminos y estos se encuentran agrupados en una lista u´nica propia de cada seccio´n. Usando la lista correspondiente de la seccio´n procesada, este u´ltimo filtro devuelve un vector con el nu´mero de veces que cada te´rmino relevante apa- rece en el conjunto de lexemas encontrados en la pa´gina Web. En otras palabras, cada uno de los componentes i del vector indica el nu´mero de veces que el te´rmino relevante t. aparece en el conjunto de lexemas produci- dos.
Puede observarse que el conjunto de algoritmos usa- dos por la tarea de preprocesamiento son procedimien- tos bien entendidos y relativamente baratos en te´rminos de recursos computacionales. De hecho, la complejidad de la tarea de preprocesamiento es lineal con el taman˜o del documento HTML. Adema´s, si bien las te´cnicas de preprocesamiento son simples, ellas son lo suficiente- mente inteligentes como para extraer la mayor´ıa de ca- racter´ısticas importantes de cada pa´gina. Es tambie´n im- portante notar que nuestra extraccio´n de caracter´ısticas reduce la dimensionalidad del problema al sintetizar un nu´mero pequen˜o de caracter´ısticas relevantes. Esta re- duccio´n de dimensionalidad puede ser ajustada dina´mi- camente en funcio´n de la cantidad de te´rminos que se escoja para representar cada clase.
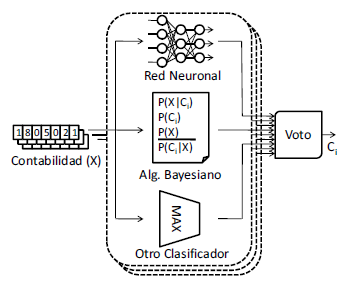
Clasificacio´n
Clasificacio´n. La tarea de clasificacio´n esta´ esquemati- zada en la figura 2. Como se observa en dicha figura, ca- da vector contabilizando el nu´mero de lexemas relevan- tes dentro de cada pa´gina Web es presentado por sepa- rado a su conjunto de clasificadores (embolsamiento) de manera simulta´nea. Cada vector es entonces clasificado por tres modelos independientes previamente entrena- dos. En nuestro clasificador se han usado redes neuro- nales, algoritmos bayesianos y la mayor´ıa de te´rminos.
La red neuronal usa un esquema de recordacio´n sin rea- limentacio´n que fue entrenado mediante el algoritmo de retro-propagacio´n del error. Retro-propagacio´n es un me´todo comu´n de aprendizaje supervisado basado en el me´todo del gradiente descendente [8]. Con relacio´n a los algoritmos bayesianos, nuestro clasificador usa el clasificador ingenuo de Bayes, el mismo que aplica el teorema de Bayes asumiendo total independencia probabilıstica entre sus variables. Este clasificador puede ser entrenado de manera bastante eficiente y trabaja mu- cho mejor de lo esperado en varias situaciones comple- jas del mundo real [9]. Finalmente, la mayor´ıa de te´rmi- nos es un clasificador elemental que asigna una pa´gina a una clase usando u´nicamente el lexema con mayor repeticio´n dentro de la contabilizacio´n generada por la tarea de preprocesamiento.
Puede observarse que la complejidad de clasificacio´n de estas tres te´cnicas es bastante baja, especialmente el clasificador bayesiano y el uso de la mayor´ıa de te´rminos. En conjunto, a trave´s del uso de embolsamiento se genera un clasificador bastante robusto y relativamente exacto que decide la clase final mediante una votacio´n proporcional entre cada una de los clasificadores indivi- duales y cada una de las secciones de la pa´gina Web.
Entrenamiento
Entrenamiento. Este es un proceso que se realiza fue- ra de l´ınea por una sola ocasio´n. Es una tarea demora- da y depende directamente del nu´mero de pa´ginas Web de entrenamiento seleccionadas. De cualquier forma, el proceso de entrenamiento inicia obteniendo el conjunto de lexemas ma´s relevantes a cada catego´ıa. Para ello, ca- da pa´gina del conjunto de entrenamiento es preprocesa- da hasta convertirla en un conjunto de lexemas. Una vez que todas las pa´ginas se han convertido en conjuntos de lexemas, se procede a calcular los coeficientes TFIDF de cada lexema existente en los docuementos de entre- namiento. Para finalizar esta primera parte, se ordenan los valores TFIDF dentro de cada categor´ıa y se escojen los lexemas correspondientes a los valores TFIDF ma´s altos.
El nu´mero de lexemas escogidos para cada categor´ıa es un para´metro variable que sin duda generara´ resultados diferentes durante el proceso de clasificacio´n de nuevas pa´ginas Web.
Una vez escogidos los lexemas ma´s relevantes a cada clase y combinados en listas u´nicas dependientes de la seccio´n procesada, se terminan de preprocesar los con- juntos de lexemas usados para entrenamiento hasta con- vertirlos en vectores que contabilizan el nu´mero de le- xemas relevantes que posee cada pa´gina. Estos vectores son entonces usados para entrenar tanto la red neuronal como el clasificador bayesiano, antes descritos.
| Categor´ıas | Aciertos ( %) |
| Arte | 88 |
| Negocios | 82 |
| Computadores | 86 |
| Educacio´n | 86 |
| Entretenimiento | 84 |
| Gobierno | 80 |
| Salud | 84 |
| Noticias | 80 |
| Deportes | 82 |
| Referencia | 78 |
| Ciencia | 82 |
| Sociolog´ıa | 80 |
| Sociedad | 84 |
| Promedio | 83 |
Evaluacio´n
Con la finalidad de evaluar el clasificador propuesto, he- mos desarrollado un prototipo inicial basado en la plata- forma Java. Ma´s espec´ıficamente, se utilizo´ el JDK 1.6 ejecutando sobre una ma´quina Pentium 4 con 1MB de memoria RAM y con el sistema operativo Linux (kernel 2.6.24).
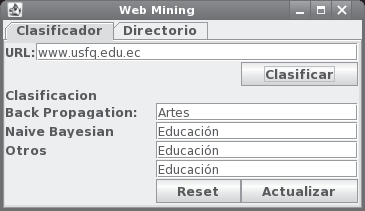
La implementacio´n del sistema clasificador incluye seis clases fundamentales que permiten el uso de una inter- face gra´fica como la presentada en la figura 3. El proce- so de entrenamiento usa otras cuatro clases adicionales para el ca´lculo de los coeficientes TFIDF y el entrena- miento de los clasificadores correspondientes. Adema´s de clasificar cualquier pa´gina Web individual, nuestro prototipo mantiene un directorio con todas las pa´ginas ya clasificadas.
La configuracio´n inicial del prototipo accesa un listado de 1300 documentos HTML previamente clasificados por el directorio de Yahoo! en 13 categor´ıas ba´sicas [3]. Cada categor´ıa contribuye con 100 pa´ginas Web al lista- do general. De todas las 1300 pa´ginas pre-clasificadas, se usaron 910 (70 %) para el proceso de entrenamiento y las restantes 390 (30 %) para la verificacio´n de exactitud del clasificador.
Durante el proceso de entrenamiento se escogieron u´ni- camente los cinco te´rminos ma´s significativos a cada clase de acuerdo al valor de sus coeficientes TFIDF. De esta manera, se termino´ generando vectores de 65 en- teros para cada una de las 910 pa´ginas de entrenamien- to. Esos vectores fueron entonces usados para entrenar los diferentes clasificadores individuales que son usados mediante el esquema de embolsamiento.
El cuadro 1 muestra los resultados obtenidos con rela- cio´n a la exactitud del clasificador una vez que las 390 pa´ginas de prueba fueron aplicadas al sistema entrena- do. Este cuadro resume los resultados porcentuales den- tro de cada categor´ıa y el valor promedio global.
Con relacio´n al tiempo de ejecucio´n, se pudo determi- nar que su mayor costo se encuentra en la descarga de la pa´gina Web antes que en el procesamiento de la mis- ma. En otras palabras, nuestra aplicacio´n se encuentra al momento limitada por la latencia de la red antes que por la velocidad de procesamiento.
Conclusiones
El presente trabajo demuestra la importancia que esta´ ad- quiriendo la tarea de clasificacio´n de pa´ginas Web y lo compleja que puede llegar a ser dicha tarea. Existe la ne- cesidad de balancear exactitud con desempen˜o y hacia esa meta apunta el presente trabajo. Mediante la selec- cio´n de te´cnicas de preprocesamiento simples se ha lo- grado extraer informacio´n cr´ıtica de cada uno de los do- cumentos HTML y posteriormente discriminarlos con una exactitud bastante buena.
Como trabajos futuros en la misma direccio´n destaca- mos el refinamiento del prototipo inicial para permitir otros algoritmos de clasificacio´n dentro del embolsa- miento y la variacio´n del nu´mero de caracter´ısticas usa- das para discriminar entre categor´ıas diferentes.
Referencias bibliográficas
[1] Han, J. and Kamber, M. 2006. Data Mining – Con- cepts and Techniques, Morgan Kaufmann Publishers, San Francisco, CA, 2nd edition.
[2] Pant, G. and Menczer, F. 2003. Topical crawling for bu- siness intelligence. In ECDL pp. 233–244.
[3] Yahoo! 2008. Yahoo Directory. http://dir.yahoo. com.
[4] Ambrosini, L., Cirillo, V., and Micarelli, A. 1997. A hy- brid architecture for user-adapted information filtering on the World Wide Web. In Proceedings of the 6th Inter- national Conference on User Modeling pp. 59–61.
[5] Paez, S., Pasmay, F., and Carrera, E. V. 2008. Improving personalized web search. Technical Report (work in pro- gress). Department of Systems Engineering, University San Francisco of Quito.
[6] Joachims, T., Freitag, D., and Mitchell, T. M. 1997. Web Watcher: A tour guide for the World Wide Web. In IJCAI (1) pp. 770–777.
[7] Qi, X. and Davison, B. D. 2007. Web page classification: Features and algorithms. Technical Report LU-CSE-07-
[8] Gupta, M. M., Jin, L., and Homma, N. 2003. Static and Dynamic Neural Networks, Wiley-Interscience, Hobo- ken, NJ, 1st edition.
[9] Zhang, H. 2004. The optimality of Na¨ıve Bayes. In Va- lerie Barr and Zdravko Markov, (ed.), FLAIRS Confe- rence, AAAI Press.
[10] Breiman, L. 1996. Bagging predictors. Machine Lear- ning. 2(24), 123–140.
[11] Singhal, A., Salton, G., Mitra, M., and Buckley, C. 1996. Document length normalization. Information Processing and Management. 5(32), 619—-633.
[12] Shen, D., Chen, Z., Yang, Q., Zeng, H.-J., Zhang, B., Lu, Y., and Ma, W.-Y. 2004. Web-page classification through summarization. In Proceedings of the 27th Annual Inter national Conference on Research and Development in Information RetrievalNew York, NY, USA: ACM Press. pp. 242–249.

