

Localización y reconocimiento de señales de tráfico del Ecuador: Casos Pare y Ceda el Paso
Ecuadorian traffic sign localization and recognition: Stop and Yield cases
ACI Avances en Ciencias e Ingenierías
Universidad San Francisco de Quito, Ecuador
Recepción: 12 Diciembre 2017
Aprobación: 10 Mayo 2018
Resumen: En el mundo y en el Ecuador, las altas tasas de accidentes de tráfico son generadas, principalmente, por la falta de respeto a la normativa vial por parte de los usuarios viales, generando costos humanos y materiales de importancia. En este sentido, la localización y el reconocimiento de las señales de tráfico es esencial para la construcción de dispositivos capaces de prevenir situaciones gue puedan generar accidentes de tráfico. Por lo tanto, en este trabajo se presenta un nuevo enfogue para la construcción de un sistema para la detección de señales de tráfico, usando las siguientes innovaciones, i) un método de segmentación por color para la generación de regiones de interés (ROIs) basado en los algoritmos k-NN con Km - means, ii) una nueva versión del descriptor HOG (Histograms of oriented gradients) para la extracción de características, y iii) el entrenamiento del algoritmo SVM no-lineal para multi-clasificación. El enfogue propuesto ha sido probado sobre las señales de tráfico ecuatorianas de Pare y Ceda el Paso. Un sin número de experimentos han sido desarrollados sobre varias secuencias de videos capturadas con un vehículo experimental en condiciones reales de conducción en varias ciudades ecuatorianas, bajo diferentes condiciones de iluminación como son normal, soleado y nublado. Este sistema ha mostrado un rendimiento global de 98.7% para la segmentación, 99.49% para la clasificación y una precisión del 96% para la detección.
Palabras clave: Señales de tráfico, Ecuador, accidentes, K - means, K- NN, SVM, HOG.
Abstract: In the world and in Ecuador, the high-rise rates of traffic accidents are caused by the lack of respect for regulations by road users, by generating important human and material costs. In this sense, the localization and recognition of traffic signs is essential for building devices capable of preventing situations that can generate traffic accidents. Therefore, in this work a new system for traffic signs detection is presented using the following innovations: i) color segmentation for regions of interest (ROIs) generation based on k- NN with Km - means, ii) a new version of the HOG descriptor for feature extraction and Hi) SVM training for stage multi-classification. The proposed approach has been specialized and tested on Ecuadorian Stop and Yield (Give-way) signs. Many experiments have been carried out over an experimental vehicle in real driving conditions, under different lighting changes such as normal, sunny and cloudy.This system has showed a global performance of 98.7% for segmentation, 99.49% for classification and an accuracy of 96% for detection.
Keywords: Traffic sign, Ecuador, accidents, Km - means, K-NN, SVM, HOG.
INTRODUCCIÓN
Actualmente, el Ecuador dispone de la mejor red vial de Suramérica [1], sobre ésta se ubican las señales de tráfico reglamentarias de Pare y Ceda el Paso, preferentemente, en las intersecciones viales, redondeles y aproximaciones por vías secundarias. A pesar de esta importante infraestructura, durante en el año 2015, el 13.75% de todos los accidentes de tráfico sucedieron en las intersecciones viales [2] generando el 8.14% de las personas fallecidas bajo este percance.
Por ello los sistemas de detección de señales de tráfico (SDST) toman cada vez mayor importancia [3], [31] para reducir los accidentes de tráfico [4], Sin embargo, estos sistemas aún están lejos de ser perfectos, y deben ser especializados por países, adaptados a las particularidades del diseño de la señalética de tráfico de cada nación [5],
Por lo tanto, en esta investigación se presenta un SDST especializado en dos tipos de señales del Ecuador como son Pare y Ceda el Paso. Para su implementación se han utilizado modernas técnicas de visión por computador e inteligencia artificial con el fin de cubrir todos los casos gue se presentan en la conducción durante el día, como son: variabilidad de la iluminación, oclusión parcial y deterioro de las señales.
Este documento está organizado de la siguiente manera. La primera sección corresponde a la motivación gue ha generado esta investigación, donde además se incluyen los trabajos previos en la detección de señales de tráfico presentes en la literatura. A continuación, el apartado dos describe un nuevo sistema para la detección de señales de tráfico para el caso de las señales de tráfico ecuatorianas de Pare y Ceda el Paso. La siguiente sección exhibe los resultados experimentales en condiciones reales de conducción. Finalmente, la última parte está dedicada a las conclusiones y los trabajos futuros.
Para la detección automática de las señales de tráfico se suele dividir al problema en dos partes, segmentación/detección y reconocimiento/clasificación [6], En el primer caso, una de las características predominantes, en el espectro visible, es el color, donde se han utilizado espacios de color y distintas técnicas de visión por computador para generar regiones con alta posibilidad de contener una señal de tráfico. En el segundo escenario, se han utilizado algunos métodos para la extracción de características en conjunto con un algoritmo de aprendizaje-máquina [7–9], para así clasificar y reconocer las señales.
Segmentación para la generación de ROIs: La mayoría de las técnicas basadas en color buscan ser robustas frente a las variaciones de iluminación. Así Salti et al. [10] han utilizado tres espacios de color derivados de RGB, el primero para resaltar las señales de tráfico con predominancia de los colores azules y rojos, el segundo es para las señales con rojo intenso y el tercero para los azules vivos. Li et al. [11] han construido un espacio donde resaltan los objetos dominados por los colores azul-amarillo y verde-rojo, sobre el cual, utilizando el algoritmo de agrupamiento K-means [12] construyen un método de clasificación por color para la generación de ROIs. Nguyen et al. [3] han utilizado el espacio HSV con varios umbrales para generar un conjunto de ROIs buscando colores rojos y azules. Lillo et al. [13] han utilizado los espacios L*a*b*y HSI para detectar señales donde predominan los colores rojo, blanco y amarillo, usando las componentes a*y b* han construido un clasificador para estos colores. Chen and Lu. [14] han utilizado multi-resolución y técnicas AdaBoost para fusionar dos fuentes de información, visual y localización espacial; en la visual construyen dos espacios de color basados en RGB denominados mapas salientes de color, en la espacial han usado el gradiente con distintas orientaciones. Finalmente, Han et al. [15] han usado la componente H del espacio HSI, donde han generado un intervalo, donde resaltan las señales de tráfico, para construir una imagen en grises donde se localizan las ROIs.
Clasificación/Reconocimiento: Esta etapa se divide en dos partes: i) método de extracción de características y, ii) elección del algoritmo de clasificación.
En el primer caso se tiene una amplia variedad de propuestas. Así Salti et al. [10], Huang et al. [16], Shi and Li [35] han utilizado el descriptor HOG [17] con tres variantes especializadas en señales de tráfico. Li et al. [11] han usado el descriptor PHOG, gue es una variación de HOG. Lillo et al. [13] han implementado la extracción de características usando la transformada discreta de Fourier. Han et al. [15] utilizaron el método SURF (Speeded Up Robust Features) [18], Chen and Lu. [14] han utilizado DSC (Discrimiative Codeword Selection) iterativo para la generación de características. Mongoose et al. [5] han implementado ICF (Integral Channel Features) and ACF (Aggregate Channel Features). Pérez et al. [6] usaron PCA (Principal Component Analysis) para la reducción de la dimensión y la elección de características. Finalmente, Lau et al. [19] usaron una ponderación de los píxeles vecinos.
En la segunda cuestión, los algoritmos preferidos son: SVM [9], [12], usado en los trabajos de Salti et al. [10], Li et al. [11], Lillo et al. [13] y Shi and Li [35], SVR en Chen and Lu [14], k - NN [12] implementado en las investigaciones de Han et al. [15], Redes neuronales artificiales, empleadas por Huang et al. [16] con el caso ELM (Extrem Learning Machine) y Pérez et al. [6] con la implementación MLP (Multi-Layer Perceptron). Adaboots con árboles de decisión utilizados en el trabajo de Mogelmose et al. [5],
En los últimos años, las técnicas basadas en aprendizaje profundo van ganando mayor importancia, tanto es así gue CNN (Convolutional Neural NetWork) y sus variaciones están siendo utilizadas para la clasificación automática, donde el vector de características se extrae sin intervención humana, en este caso están Lau et al. [19] y Zhu et al. [20], Zuo etal. [32],
Bases de datos: Cada país tiene sus propias normativas en cuanto a la señalética de tráfico, divida en las categorías de informativas, obligatorias, prohibitivas y advertencia [5], [10], [13], [14], [20], En la actualidad, las principales bases de datos corresponden a países como Alemania [6], [10], [16], Italia [10], España [13], Japón [3], Estados Unidos [5], Suecia [20] o Malaysian [19], Esto demuestra gue no existe información de los países en desarrollo, como es el caso del Ecuador, en lo gue respecta a las señales de tráfico ni de la infraestructura vial; esto genera un reto para levantar este tipo de información relevante para la seguridad vial.
Sistemas comerciales: Las empresas del sector automotriz están desarrollado prototipos para la detección de señales de tráfico, dos de ellas son Mobileye [33], y Continental [34], Con estos sistemas, estas empresas están incursionando en el campo de la conducción autónoma y los vehículos inteligentes.
MATERIALES Y MÉTODOS
El esguema del sistema propuesto se presenta en la Figura 1, donde están las etapas de segmentación (localización) y reconocimiento (clasificación). En el proceso de segmentación se genera un conjunto de ROIs, gue será enviado a la etapa de clasificación para su reconocimiento. En esta propuesta únicamente se trabaja en el caso restringido de las señales de tráfico Pare y Ceda el Paso gue forman parte de las señales de prohibición.
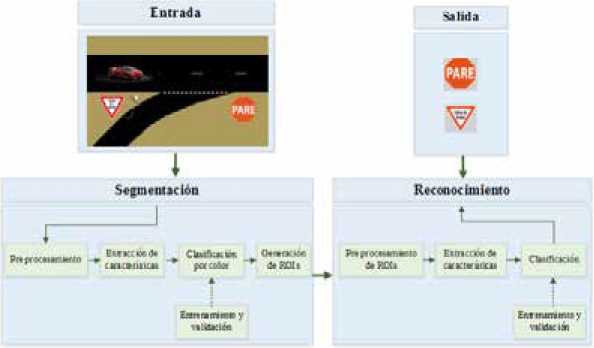
Esquema propuesto para la localización y reconocimiento de señales de tráfico en intersecciones viales en el Ecuador, para los casos Pare y Ceda el Paso.
A. Segmentación y generación de ROIs
La segmentación se realiza discriminando el color rojo del fondo, es decir, del resto de colores. Experimentalmente se ha elegido el espacio de color RGB Normalizado (RGBN) porgue presenta una distribución más compacta en los canales Bny Gn, cuyos valores se encuentran en los intervalos y respectivamente. La Figura 2(a) muestra las distribuciones de las clases, donde el rojo representa la clase de interés y el azul identifica la clase de no interés. La Figura 1 (izquierda) muestra el esquema de segmentación que se describe a continuación.
Utilizando los métodos de Calinski- Harabasz [21], Davies-Bouldin [22], Gap [23] y Silhouettes [24] se ha llegado a determinar el valor eficiente de Km, obteniendo los valores de y para las clases rojo y no rojo (otros colores), respectivamente. La Figura 2(b) muestra los centroides de las dos clases. Para generar esta figura se han utilizado muestras en tres condiciones de iluminación: soleado, normal y obscuro.
| Característica | Valor mínimo | Valor máximo |
| Área | 400 pixeles | 10000 pixeles |
| Relación ancho/alto | 0.6 | 1.4 |
| Distancia de referencia | 20 metros | 5 metros |
Características geométricas que debe cumplir una ROI en una imagen de tamaño 640x480.

Elección del parámetro K en K-NN.
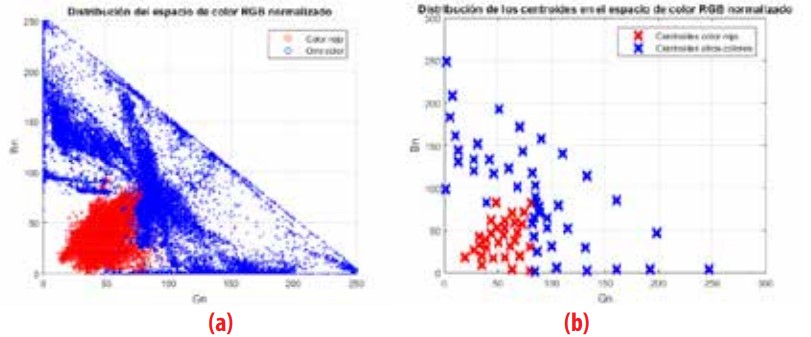
Distribución del color en el espacio RGB normalizado, (a) clases de interés y no interés, (b) centroides generadas con Km – means.
B. Reconocimiento
En esta etapa se clasifican las ROIs provenientes de la etapa de segmentación, para determinar si corresponden a una señal de Pare, Ceda el Paso u otro objeto.
La Figura 1 (derecha) muestra el esguema de reconocimiento, gue consta de las siguientes partes:
En total se evalúan 60 casos combinando los puntos 2 y 3, de los cuales se extraen los gue generan mejores resultados en la siguiente sección.

Variación del tamaño de celda sobre imágenes de tamaño 32x32 pixeles: (a) 2x2, (b) 4x4, (c) 8x8 (d) 16x16.
RESULTADOS
A. Sistema de percepción y procesamiento
El sistema de detección de señales de trafico total se presenta en la Figura 4, el mismo que está compuesto por una cámara USB (l), una pantalla de visualización (2) y una computador de procesamiento (3), todo esto, montado sobre el vehículo experimental ViiA, que incorpora una fuente de poder 12V-120AC (4), para alimentar el sistema.

Sistema de detección de señales de tráfico del Ecuador, en los casos Pare y Ceda el paso.
Actualmente, este sistema es de fácil instalación en cualquier tipo de vehículo y no interfiere con las labores de conducción, debido a su reducido tamaño.
B. Base de datos de entrenamiento, validación y experimentación
Las bases de datos de entrenamiento y de validación han sido construidas con imáqenes de señales de tráfico del Ecuador, tomadas en las ciudades de Latacunqa, Quito y Sanqolquí, en distintas condiciones de iluminación durante el día. Estas condiciones corresponden a los casos de normal, soleado y nublado. En la Tabla 3 se indica el tamaño de los conjuntos deentrenamientoy de validación obtenidos por medio del método de Holdout [28] y en la Fiqura 5 se observan varios ejemplos positivos y neqativos.
| Número de muestras | Total | |||
| Pare | Ceda el Paso | Negativas | ||
| Entrenamiento | 700 | 700 | 2800 | 4200 |
| Validación | 300 | 300 | 1200 | 1800 |
| Total | 1000 | 1000 | 4000 | 6000 |
Tamaño de los conjuntos de entrenamiento y validación por tipos de señal.
Para incrementar el tamaño del conjunto de entrenamiento se rotaron aleatoriamente las imáqenes hasta obtener un total de cinco veces el tamaño oriqinal. De esta manera se incrementa la variabilidad de la base de datos.

Ejemplos de la base de datos de señales de tráfico del Ecuador en distintas condiciones de iluminación y de estado, (a) Pare, (b) Ceda el Paso, y (c) ejemplos negativos.
Posteriormente para verificar el funcionamiento del sistema se construyó una base de datos con vídeos en situaciones reales de conducción, en el espectro visible. Esta base está constituida por cinco ejemplares en diferentes condiciones de iluminación, donde las señales han sido localizadas manualmente con fines de evaluación [25],
C. Análisis de resultados
Para el caso de la segmentación por color, el algoritmo de clasificación genera un AUC de 0.986, con k = 4y Kn = 30 para la clase de color rojo y k = 3 y Kn = 40 para la clase otros colores.
Para el caso de la clasificación, los mejores parámetros del descriptor HOG son: celdas de 8 x 8 píxeles, blogues de 2 x 2 celdas con solapamiento simple, orientaciones sin signoy SVM polinomial de parámetros C = 215, r = 0, d = 3, y = 1/m, con rn es el tamaño del vector de características. En la Tabla 4 se presentan los resultados para el caso de 8 x 8 píxeles, donde el mejor resultado se encuentra resaltado.
| Orientaciones | Lineal | Tipo de núcleo Polinómico | RBF |
| 3 | 0.9603 | 0.9913 | 0.9755 |
| 6 | 0.9784 | 0.9947 | 0.9834 |
| 9 | 0.9798 | 0.9949 | 0.9784 |
| 12 | 0.9762 | 0.9921 | 0.9827 |
| 15 | 0.9834 | 0.9971 | 0.9819 |
Resultados de clasificación con características HOG con celdas de 8x8 píxeles en todas las orientaciones.
Para medir la capacidad de detección, la curva DET [30], gue gráfica la tasa de falsos negativos (taza de pérdida) versus la tasa de falsos positivos, en escala logarítmica en el rango de 0.01-1, se presenta en la Figura 6, en ella se observa gue el mejor desempeño se realiza en días normales con una tasa de pérdidas del 13 y la peor ejecución es en días soleados con una taza de pérdidas del 28, esto se puede observar en la Tabla 5.
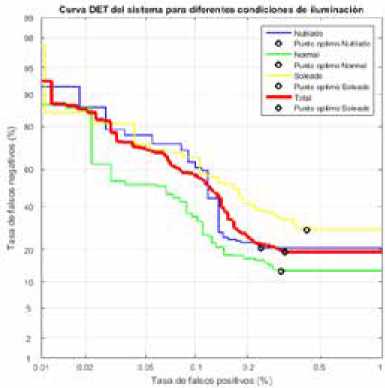
Curva DET del sistema de detección de señales de tráfico.
El sistema tiene un excelente desempeño, con una precisión del 96. Varios ejemplos generados por el sistema se lo observan en la Figura 7 y la Figura 8.
| TRPa | TFNb | TRNC | TFPd | Exactitud | Precisión | |
| Día normal | 0.87 | 0.13 | 0.997 | 0.003 | 0.98 | 0.97 |
| Día soleado | 0.72 | 0.28 | 0.995 | 0.005 | 0.97 | 0.90 |
| Día nublado | 0.79 | 0.21 | 0.997 | 0.003 | 0.97 | 0.96 |
| Sistema total | 0.81 | 0.19 | 0.997 | 0.003 | 0.98 | 0.96 |
Resultados del sistema de detección de señales de tráfico en diferentes escenarios de iluminación durante el día.
aTasa de Reales Positivos, bTasa de Falsos Negativos, cTasa de Reales Negativos, dTasa de Falsos Positivos

Resultados del sistema de detección de señales de tráfico en los casos Pare y Ceda el Paso, durante un día soleado; (a) imagen de entrada, (b) ROIs y (c) detecciones.

Resultados del sistema de detección de señales de tráfico en los casos Pare y Ceda el Paso, durante un día soleado; (a) imagen de entrada, (b) ROIs y (c) detecciones.

Resultados del sistema de detección de señales de tráfico en los casos Pare y Ceda el Paso, durante un día obscuro; (a) imagen de entrada, (b) ROIs y (c) detecciones.
D. Tiempos de cómputo
En la Tabla 6 se presenta el tiempo de cómputo del sistema total. Estos resultados son los valores promedios del procesamiento de 37185 (distribuidos de la siguiente manera 9999 en soleado, 14744 en normal y 12442 en nublado) imágenes de tamaño 640 x 480 píxeles.
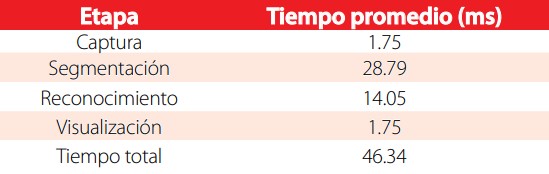
Tiempos de cómputo total del sistema de detección de señales de tráfico del Ecuador en los casos Pare y Ceda el Paso.
Esto demuestra que el sistema es capaz de trabajaren tiempo cuasi-real, es decir, puede procesar aproximadamente 21 imágenes por segundo.
DISCUSIÓN
En este trabajo de investigación se aportó con la construcción de una nueva base datos para el reconocimiento de señales de tráfico del Ecuador, en los casos Pare y Ceda el Paso. Esta información está disponible para el libre uso de la comunidad científica en https://gitlab.com/mjflores/Ecuadorian_Traffic_Sign_Stop_and_Yield. De igual forma, hemos presentado el desarrollo de un nuevo método de segmentación por color para la generación de ROIs utilizando el clasificador k- NN junto con el algoritmo de agrupamiento Km - means. Esta implementación cubre eficientemente los escenarios de iluminación normal, soleado y obscuro, durante el día. Se incluye la distancia como un parámetro de referencia para la preselección de ROIs, en el rango de 5 a 20 metros de distancia. Así, esta propuesta alcanza una tasa de clasificación del 987%en la discriminación entre los píxeles de interés y el fondo.También hemos implementado una nueva versión del descriptor EIOG gue consiste en celdas de 8 x 8 píxeles, blogues de 2 x 2 celdas con solapamiento simple y orientaciones sin signo. La tasa de clasificación es del 99,49% usando SVM con ntícleo polinómico.
Dos aspectos clave de este trabajo son la construcción de un sistema de detección de las señales de tráfico del Ecuador, especializado en los casos Pare y Ceda el Paso. La curva DET indica gue su desempeño es del 96%, de manera gue es competitivo respecto a las propuestas presentes en el estado del arte. La construcción de un asistente de ayuda a la conducción gue trabaja en tiempo cuasi-real, es decir, a 21.58 fotogramas por segundo, de fácil instalación en un vehículo de uso cotidiano.
A futuro se extenderá esta metodología a los siguientes casos:
Manejo de oclusiones para detectar señales parcialmente visibles bajo las distintas condiciones de iluminación.
Para la detección de las señales de límites de velocidad del Ecuador.
Agradecimientos
Los eguipos utilizados en para el desarrollo de este proyecto han sido financiados por la empresa Tecnologías l&H. Además, agradecemos a los revisores anónimos por su valioso aporte ya gue han contribuido significativamente en la mejora de este manuscrito.
Referencias
World Economic Forum. (2016). Global competitiveness report 2015-2016. Competitiveness rankings. A. transport infrastructure. Recuperado el 12 de noviembre de 2017 de: http://reports.weforum.org/global-competitiveness-report-2015-2016/competitiveness-rankings/#indicatorld=GCI.A.02.01
Agencia National de Transito del Ecuador. (2015) Siniestros octubre 2015. Recuperado el 12 de diciembre de 2017 de: http://www.ant.gob.ee/index.php/descargable/file/3265-siniestros-octubre-2015
Nguyen, B. I., Ryong, S. J., & Kyu, K. J. (2014, Julio). Fast traffic sign detection under challenging conditions. In Audio, Language and Image Processing (ICAUP), 2014 International Conference on (pp. 749-752). IEEE.
Shaout, A., Colella, D., & Awad, S. (2011, Diciembre). Advanced driver assistance systems-past, present and future. In Computer Engineering Conference (ICENCO), 2011 Seventh I nternat Iona I (pp. 72-82). IEEE.
Mogelmose, A., Liu, D., & Trived i, M. M. (2015). Detection of US traffic signs. IEEE Transactions on Intelligent Transportation Systems, 76(6),3116-3125.
Perez-Perez, S. E., Gonzalez-Reyna, S. E., Ledesma-Orozco, S. E., & Avina-Cervantes, J. G. (2013, November). Principal component analysis for speed limit Traffic Sign Recognition. In Power, Electronics and Computing (ROPEC), 2013 IEEE International Autumn Meeting on (pp. 1-5). IEEE.
Cortes, C, & Vapn ik, V. (1995). Support-vector networks. Machine learning, 20(3), 273-297.
R. Duda, P. Hart, and D. Stork. (2001). Pattern Classification, 2nd ed., 2001.
Cristianini, N., & Shawe-Taylor, J. (2000). An introduction to support vector machines and other kernel-based learning methods. Cambridge university press.
Salti, S., Petrelli, A., Tombari, F., Fioraio, N., & Di Stefano, L. (2015). Traffic sign detection via interest region extraction. Pattern Recognition, 48(4), 1039-1049.
Li, H., Sun, F., Liu, L, & Wang, L. (2015). A novel traffic sign detection method via color segmentation and robust shape matching. Neurocomputing, 169,77-88.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). Unsupervised learning. In The elements of statistical learning (pp. 485- 585). Springer, New York, NY.
Lillo-Castellano, J. M., Mora-Jimenez, I., Figuera-Pozuelo, C, & Rojo-Älvarez, J. L. (2015).Traffic sign segmentation and classification using statistical learning methods. Neurocomputing, 153,286-299.
Chen, T., & Lu, S. (2016). Accurate and Efficient Traffic Sign Detection Using Discriminative AdaBoost and Support vector Regression. Ifff Trans. Vehicular Technology, 65(6),4006-4015.
Han, Y., Virupakshappa, K., & Oruklu, E. (2015, Mayo). Robust traffic sign recognition with feature extraction and k-NN classification methods. In Electro/lnformation Technology (E1T), 2015 IEEE International Conference on (pp. 484-488). IEEE.
Huang,/., Yu, Y, &Gu, J. (2014, Junio). A novel method for traffic sign recognition based on extreme learning machine. \n Intelligent Control and Automation (WCICA), 2014 11th World Congress on (pp. 1451-1456). IEEE.
Dalal, N. (2006). finding people in images and videos (Doctoral dissertation, Institut National Polytechnique de Grenoble-INPG).
Bay, H., Ess, A., Tuytelaars, T., & Van Gool, L. (2008). Speeded-up robust features (SURF). Computer vision and image understanding, 110(3), 346-359.
Lau, M. M., Lim, K. H& Gopa lai, A. A. (2015, Julio). Malaysia traffic sign recognition with convolutional neural network. I n 2015 IEEE International Conference on Digital Signal Processing (DSP) (pp. 1006-1010). I EEE.
Zhu, Y., Zhang, C., Zhou, D., Wang, X., Bai, X., & Liu, W. (2016). Traffic sign detection and recognition using fully convolutional network guided proposals. Neurocomputing, 214,758-766.
Calihski, T., & Harabasz, J. (1974). A dendrite method for cluster analysis. Communications in Statistics-theory and Methods, 3(1), 1-27.
Davies, D. L, & Bouldin, D. W. (1979). A cluster separation measure. I EEE transactions on pattern analysis and machine intelligence, (2), 224-227.
Tibshirani, R., Walther, G., & Hastie, T. (2001). Estimating the number of clusters in a data set via the gap statistic. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 63(2), 411-42
Rousseeuw, P. J. (1987). Silhouettes: a graphical aid to the interpretation and validation of cluster analysis, Journal of computational and applied mathematics, 20, 53-65.
T. Fawcett. (2004). "Roc graphs: Notes and practical considerations for researchers," Machine learning, vol. 31, no. 1, pp.1-38.
Pajares Martinsanz, G., García, C, & Jesús, M. (2002). Visión por computador: Imágenes digitales y aplicaciones.
Dalal, N., & Triggs, B. (2005, Junio). Histograms of oriented gradients for human detection. In Computer Vision and Pattern Recognition, 2005. CVPR2005. IEEE Computer Society Conference on (Vol. 1, pp. 886-893). IEEE.
Kohavi, R. (1995, Agosto). A study of cross-validation and bootstrap for accuracy estimation and model selection. ln Ijcai (Vol. 14,No.2,pp. 1137-1145).
Martin, A., Doddington, G., Kamm, T., Ordowski, M., & Przybocki, M. (1997). The DET curve in assessment of detection task performance. National Inst of Standards and Technology Gaithersburg MD.
Gómez-Moreno, H., Maldonado-Bascón, S., Gil-Jiménez, R, & Lafuente-Arroyo, S. (2010). Goal evaluation of segmentation algorithms for traffic sign recognition. IEEE Transactions on Intelligent Transportation Systems, 11(4), 917-930.
Zuo, Z, Yu, K., Zhou, Q., Wang, X., & Li, T. (2017, June). Traffic signs detection based on faster R-CNN. In Distributed Computing Systems Workshops (ICDCSW), 2017 IEEE 37th International Conference on (pp. 286-288). IEEE.
Mobileye. (2018). ADAS - Mobileye. Recuperado el 12 de noviembre de 2017 de: https://www.mobileye.com/ourtechnology/adas/
Continental-automotive.com. (2018). Continental Automotive. Recuperado el 12 de noviembre de 2017 de: https://www.continental-automotive.com/en-gl/Passenger-Cars/Chassis-Safety/Advanced-Driver-Assistance-Systems/Driving-Functions/Traffic-Sign-Assist
Shi, J. H., & Lin, H. Y. (2017, Junio). A vision system for traffic sign detection and recognition. In Industrial Electronics (ISIE), 2017 IEEE 26th International Symposium on (pp. 1596-1601). IEEE.
Información adicional
CONTRIBUCIÓN DE LOS AUTORES: El diseño de la investigación, el
desarrollo y la implementación del software, la supervisión y el análisis de
los resultados experimentales corresponden a M. Flores. La implementación del
software y el desarrollo de los experimentos pertenecen a C. Conlago y J. Yunda. La redacción y revisión del manuscrito
y contrastación de la información recaen en M. Aldas y C. Flores.